Supplemental benchmark and source-availability details
This supplement documents analyses that are useful for reproducibility but are not part of the main paper's primary BioReason-Pro benchmark story. The main manuscript uses ARGO139 for RL narrative review and ARGO95 for SFT GO-term review, while ESR-ECOLI-DET-Mini is the separate Expert Synthetic Review recap positive control. The views below explain why earlier drafts used mixed SFT denominators and preserve those results for reproducibility.
S1. Cohort accounting
The main RL benchmark is ARGO139, a fixed 139-gene set listed in ../genes.csv. The main SFT term benchmark is ARGO95, the 95-gene ARGO139 subset present in the HuggingFace wanglab/protein_catalogue SFT download.
Table S1. Cohorts emitted by write_benchmark_sidecars.py.
| Cohort | Genes | Predictions | Role |
|---|---|---|---|
argo139_rl_narrative |
139 | - | Main RL narrative benchmark |
argo95_sft_terms |
95 | 955 | Main HF-catalogue SFT term benchmark |
supplement_sft_terms_argo139_mixed_sources |
139 | 10,697 | Mixed-source ARGO139 diagnostic; not a primary benchmark |
supplement_sft_terms_web_export_44 |
44 | 9,742 | ARGO139 genes absent from HF; web source includes ancestor hierarchy |
supplement_sft_narrative_hf |
45 | - | SFT narrative cross-check |
supplement_sft_terms_hf_catalogue_all |
154 | 1,358 | Full HF catalogue view |
supplement_sft_terms_union_all |
198 | 11,100 | ARGO139 plus 59 HF-only genes |
supplement_gogpt_overlap_300 |
300 | 8,910 | Separate GO-GPT overlap review |
The key availability issue is simple: the HuggingFace wanglab/protein_catalogue SFT download contained 95/139 ARGO139 genes. The remaining 44 ARGO139 genes were not present in that download. We do not fill those 44 into the primary SFT analysis, because the BioReason-Pro SFT web exports expose a much larger ancestor-rich term panel and are not comparable to the HF catalogue source.
S2. Supplemental SFT term views
Table S2. ARGO95 SFT assessment distribution, repeated from the main paper.
| Benchmark | Genes | Terms | CNN | NPI | COR | LSP | REP | UNC |
|---|---|---|---|---|---|---|---|---|
| ARGO95 (HF catalogue) | 95 | 955 | 645 (67.5%) | 101 (10.6%) | 52 (5.4%) | 37 (3.9%) | 21 (2.2%) | 99 (10.4%) |
For comparison, the mixed-source ARGO139 view is retained as a source-diagnostic table, not as a primary SFT benchmark.
Table S3. Supplemental mixed-source ARGO139 SFT assessment distribution.
| Source | Genes | Terms | CNN | NPI | COR | LSP | REP | UNC |
|---|---|---|---|---|---|---|---|---|
| HF catalogue / ARGO95 | 95 | 955 | 645 (67.5%) | 101 (10.6%) | 52 (5.4%) | 37 (3.9%) | 21 (2.2%) | 99 (10.4%) |
| Web export | 44 | 9,742 | 2,321 (23.8%) | 42 (0.4%) | 7 (0.1%) | 388 (4.0%) | 1 (0.0%) | 6,983 (71.7%) |
| Mixed-source ARGO139 total | 139 | 10,697 | 2,966 (27.7%) | 143 (1.3%) | 59 (0.6%) | 425 (4.0%) | 22 (0.2%) | 7,082 (66.2%) |
Table S4. Terms per gene in the SFT source views.
| Source | Mean terms/gene | Median terms/gene | Max terms/gene |
|---|---|---|---|
| ARGO95 / HF catalogue | 10.1 | 7.0 | 38 |
| Web export | 221.4 | 212.5 | 598 |
| Mixed-source ARGO139 total | 77.0 | 12.0 | 598 |
The all-HF view is still useful as the broadest single-source HF view, but it is not the main benchmark because 59 of those genes are outside ARGO139.
Table S5. Supplemental full HF catalogue view: 1,358 terms across 154 genes.
| Assessment | Count | % |
|---|---|---|
| CNN | 884 | 65.1 |
| UNC | 186 | 13.7 |
| NPI | 154 | 11.3 |
| COR | 59 | 4.3 |
| LSP | 50 | 3.7 |
| REP | 25 | 1.9 |
The all-source union is the broadest source-availability view, but it combines ARGO139 with 59 HF-only genes and is therefore not a paired benchmark.
Table S6. Supplemental all-source union: 11,100 terms across ARGO139 plus 59 HF-only genes.
| Assessment | Count | % |
|---|---|---|
| CNN | 3,205 | 28.9 |
| NPI | 196 | 1.8 |
| UNC | 7,169 | 64.6 |
| COR | 66 | 0.6 |
| LSP | 438 | 3.9 |
| REP | 26 | 0.2 |
S3. CAFA-style retrospective GOA agreement
We computed a retrospective CAFA-style agreement score for ARGO95 SFT GO-term predictions using current local GOA as the reference. This is not a true CAFA benchmark: ARGO95 is retrospective, there is no temporal holdout, and the BioReason-Pro SFT files do not contain model confidence scores. The score therefore treats predictions as an unranked single-threshold set and reports propagated precision/recall/F1 rather than (F_{\max}). Both predictions and reference GOA annotations are propagated over is_a and part_of ancestors from go-basic.obo, excluding the three GO aspect roots. The mixed-source ARGO139 rows are retained only as diagnostics.
Table S7. Propagated all-aspect agreement against current GOA.
| Source | Genes | Scored direct predictions | Direct GOA terms | Precision | Recall | F1 |
|---|---|---|---|---|---|---|
| ARGO95 / HF catalogue | 95 | 952 | 2,382 | 0.864 | 0.476 | 0.614 |
| Web export | 44 | 9,730 | 3,885 | 0.777 | 0.533 | 0.632 |
| Mixed-source ARGO139 total | 139 | 10,682 | 6,267 | 0.808 | 0.510 | 0.625 |
The score shows why aggregate GOA agreement is useful but incomplete. In the HF catalogue subset, 37/122 terms classified by AI-AUGR as NPI or REP are exact matches to current GOA, and 92/122 have propagated overlap with current GOA. A GOA-agreement metric would reward some of these predictions despite evidence-grounded review classifying them as wrong or frequency-biased.
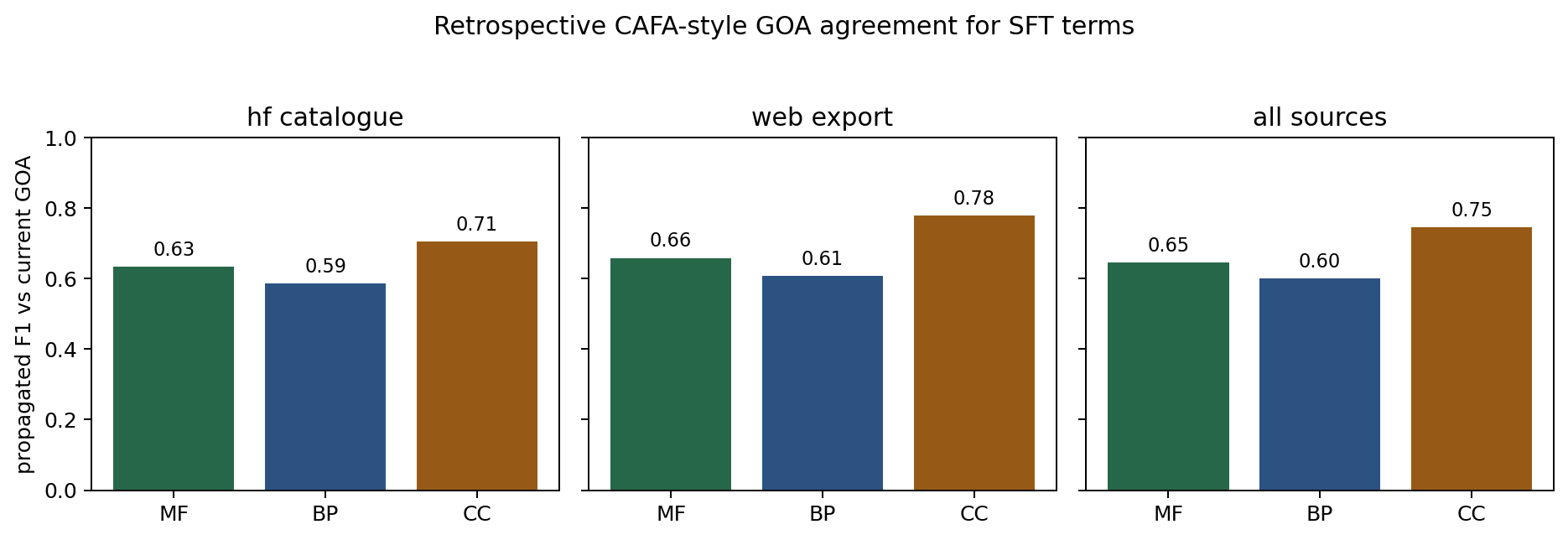
Full derived tables are in ../cafa-style/.
S4. SFT narrative cross-check
The HuggingFace SFT narrative sample contains 45 proteins, 44 of which have parseable 1-5 correctness/completeness scores. It is not paired to ARGO139 and is not used as a main result. It remains a useful cross-check: SFT narrative scores are lower than RL (correctness 2.9/5 vs. 3.7/5; completeness 2.7/5 vs. 2.9/5), and 7/45 SFT outputs contained fabricated "UniProt Summary" prose for proteins that UniProt describes only as uncharacterized.
S5. GO-GPT overlap review
The main paper removes the GO-GPT section because it is a separate 300-gene synthetic review of the upstream GO-GPT predictor, not a paired ARGO139 BioReason-Pro result. The review remains useful for showing how much apparent agreement changes when the reference set moves from raw GOA to AIGR core biology.
Table S8. GO-GPT prediction overlap at three reference levels (300 genes).
| Reference level | Terms in reference | Predictions overlapping | % of 8,910 predictions |
|---|---|---|---|
| Raw GOA | 2,967 | 1,046 | 11.7 |
| Post-AIGR-review | 2,913 | 971 | 10.9 |
| AIGR core functions only | 933 | 210 | 2.4 |
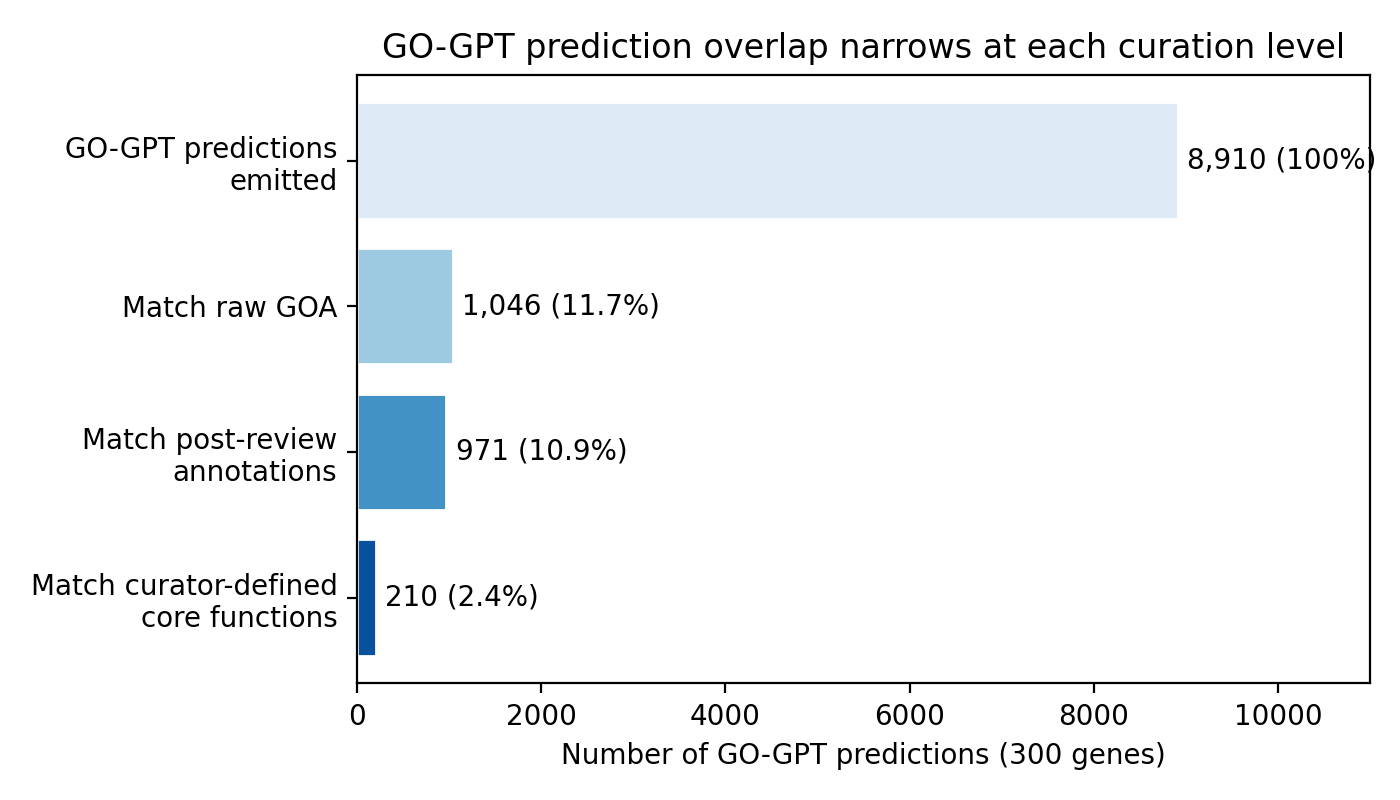
GO-GPT emitted 8,910 predictions across 300 genes (mean 29.7 per gene). Raw GOA agreement was 11.7%; agreement with AIGR core functions was only 2.4%. This is a useful illustration of the CAFA-style scoring gap, but it is not used as a main BioReason-Pro benchmark result.
S6. Reproducibility files
../genes.csv: ARGO139 member list.../argo139-species-counts.csv: ARGO139 species distribution.../argo139-curation-context-counts.csv: ARGO139 curation-context summary.../benchmark-cohorts.csv: cohort-level provenance and sizes.../benchmark-genes.csv: gene-level benchmark/source provenance.../cafa_style_argo139.py: retrospective CAFA-style SFT scorer; ARGO95 is the primary HF-catalogue row.../cafa-style/argo139_cafa_style_summary.csv: propagated and exact precision/recall/F1 summary.../cafa-style/argo139_cafa_style_per_gene_aspect.csv: per-gene/per-aspect score components.../cafa-style/argo139_prediction_goa_overlap.csv: per-prediction exact and propagated GOA-overlap diagnostics.../notebooks/02_prediction_assessments.ipynb: executable SFT term-assessment notebook.